How I run an 85,000-user AI study platform solo
A 22-year-old founder on building a production AI product without a team, using Claude Code as a small army.

Two years ago I started building StudyPDF, an AI study platform that turns lectures, slides, and PDFs into flashcards, practice exams, and study guides. Today it has 85,000 registered users, and daily active users have grown from around 100 to over 600 in the last five months. I'm 22, doing my Master's at RWTH Aachen and working as a Software Engineering Working Student in Cologne.
I'm writing this because I think building "solo with AI" is more powerful than many think. Here's what it actually looks like.
How it started
In the summer of 2023. I had just finished CS50, was halfway through my Bachelor's in mechanical engineering, and I tried to use AI for my exam prep. It worked badly. ChatGPT couldn't even take PDF uploads back then. Me and my friends created our flashcards manually and exported them to Anki. We were pasting lecture screenshots into new chats and asking questions. I thought: this should not be this bad.
I built the first version in about three weeks. It was rough. You uploaded a PDF, I ran OCR, chunked it, embedded it into a vector store, and asked GPT-4 to generate flashcards. The first hundred users came through reels on Instagram and TikTok. Users didn't expect that they were already able to convert their long lectures at the end of 2023 into real study sets. So in the beginning, working with reels was pretty good for getting the initial users, since they got immediately hooked.
I had no idea what I was doing on the infrastructure side. I'd never deployed anything to production before. The first time the database went down, I genuinely didn't know how to read logs. I learned by breaking things in front of real users, which is a humbling way to learn. Of course I had already learned and watched many videos before on how to set up production systems, how to choose between relational and non-relational databases, etc. But breaking live in production. For this you can't prepare.
Through 2024, the product slowly improved. I shipped, users signed up, I kept going. Then in March 2025, Moritz Kindler joined as co-founder, and things changed shape pretty fast. He took over most of the UI/UX work, and the curve genuinely went upward once the workload was split. Features got more polish, the brand actually started to feel like a brand, and I had headroom to focus on the AI side. A lot of what you see in the product today exists because of decisions we made together during those months.
By the end of 2025 the logistics stopped working. He was in Stockholm, I was in Aachen, both of us full-time students. We ended things cleanly, no drama, and from January 2026 onward I've been running StudyPDF alone again. Most of the story I'm telling in this post is about being one person, because most of the two years has been that. But the bump Moritz brought in 2025 is real, and I want to name it and thank him here again. He is a great product designer and invented StudyPDF's visual identity of today.
The shape of being solo
When people say "solo founder," they usually mean "I write all the code." That's the easy part. Solo means you are also support, marketing, legal, finance, and customer success. Solo means at 11pm on a Tuesday someone in Brazil emails you saying their flashcards generated in the wrong language, and there is exactly one person who can answer.
A typical day right now: I wake up around 8, scan production alerts and user emails, spend two hours on my Master's, then four to five hours on StudyPDF, usually split between one bigger feature and a stack of small things. Evenings are for either reviewing what shipped that day or, increasingly, just touching grass.
Two rules shape everything:
First: if a feature needs more than two hours of maintenance per month, it gets cut. I have killed features users liked because they were eating my time. Solo means your time is the actual resource, not money.
Second: if a workflow can't be handled by a Claude Code agent, it's probably designed wrong. This sounds like AI-hype until you've done it. I'll get to this in a second.
The architecture, briefly
The product looks simple from the outside: you upload a document, you get study materials. Under the hood, the interesting part is what we built about a year in, when the models got better and my expectations did too.
The early version had a problem. Users were uploading 400-page lecture decks. A single course might be 10 lectures of 200 slides each. If you just embed the whole thing and ask a model to generate questions, you get one of two failure modes: irrelevant questions about footers and slide numbers, or a model that misses entire concepts because it's drowning in noise.
So I built a two-stage extraction pipeline. The first stage is expensive: a reasoning model reads the entire document and extracts topics, and within each topic, the concepts that are discussed, applied, or explained. This becomes the foundation of everything. Every flashcard, every practice question, every future chat message about the document gets grounded in a specific concept inside a specific topic of the document.
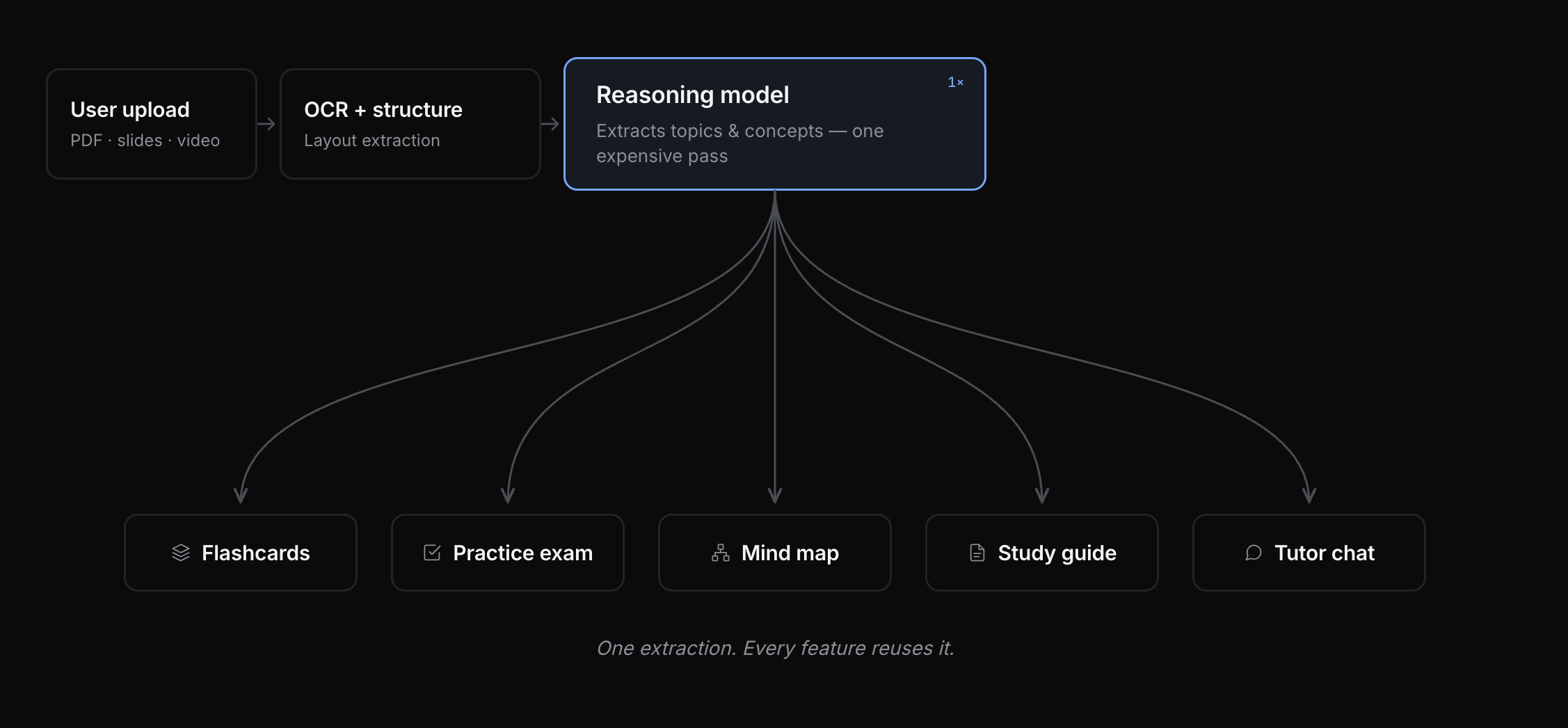
One extraction. Every feature reuses it.
That's the engineering view. The reason the structure earns its keep isn't in the diagram. It's what a user sees on the other side of it. Not a JSON blob, but a study guide that already knows what's in their document and where every idea lives. Here's one from a Bayesian inference PDF a student uploaded last week:
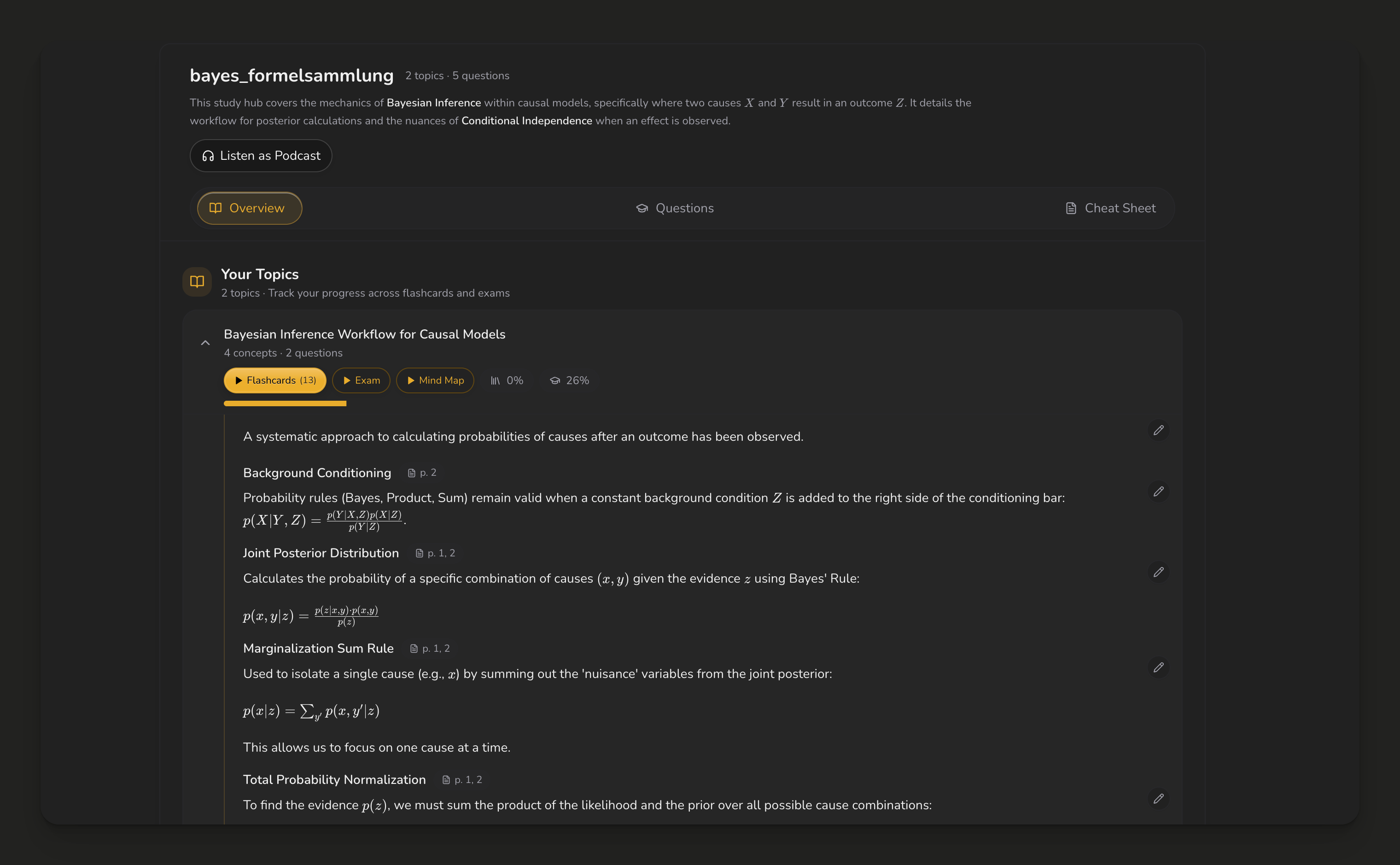
Each top-level entry is a topic; each bold heading is a concept, with the page it came from. Flashcards, practice exams, and mind maps are all generated from this same tree.
This was supposed to be a quality fix. It turned out to be a cost fix too. The deep analysis happens once, and then cheaper models reuse the structured output for every feature. Every new feature I ship, and there are a lot of them, plugs into the same topic-and-concept graph. Then, the features use embeddings of the relevant "concept" chunks to retrieve the relevant context. The expensive reasoning model runs once per document, not once per feature.
I won't dump the full architecture here, but the rest of the stack is boring on purpose: TypeScript, Next.js, PostgreSQL, Pinecone for vectors, Cloudflare R2 for storage (S3 egress fees would kill the margins), Anthropic and OpenAI APIs for everything model-related. Boring tech is what runs alone.
Claude Code as my team
This is the part I get asked about the most, so let me be specific.
I don't use Claude Code as autocomplete. I use it as an orchestration layer for the kind of work that would normally need a small team. Most of what I ship now goes through roughly this pattern: I write a short spec, point an agent at the relevant files, let it propose a plan, push back until it's actually right, then let it implement. I review the diff, I run it locally, I ship.
Three concrete examples of where this actually changes my day:
1. KPI monitoring. I run Claude Code with the PostHog MCP server connected. Instead of opening dashboards, I ask: "Did yesterday's onboarding A/B test move conversion?" or "Which referrer URLs spiked this week?" The agent pulls the numbers, summarizes, and tells me where to look. This sounds small. It is not small. It's the difference between checking metrics once a week because dashboards are tedious, and checking them every morning because asking a question is cheap. This is combined with a changelog of my daily Claude Code sessions. If a new feature was shipped, a new pricing tier introduced, or just a small UI change, the KPI agent picks it up and tries to map it to relevant metrics to see if we actually improved.
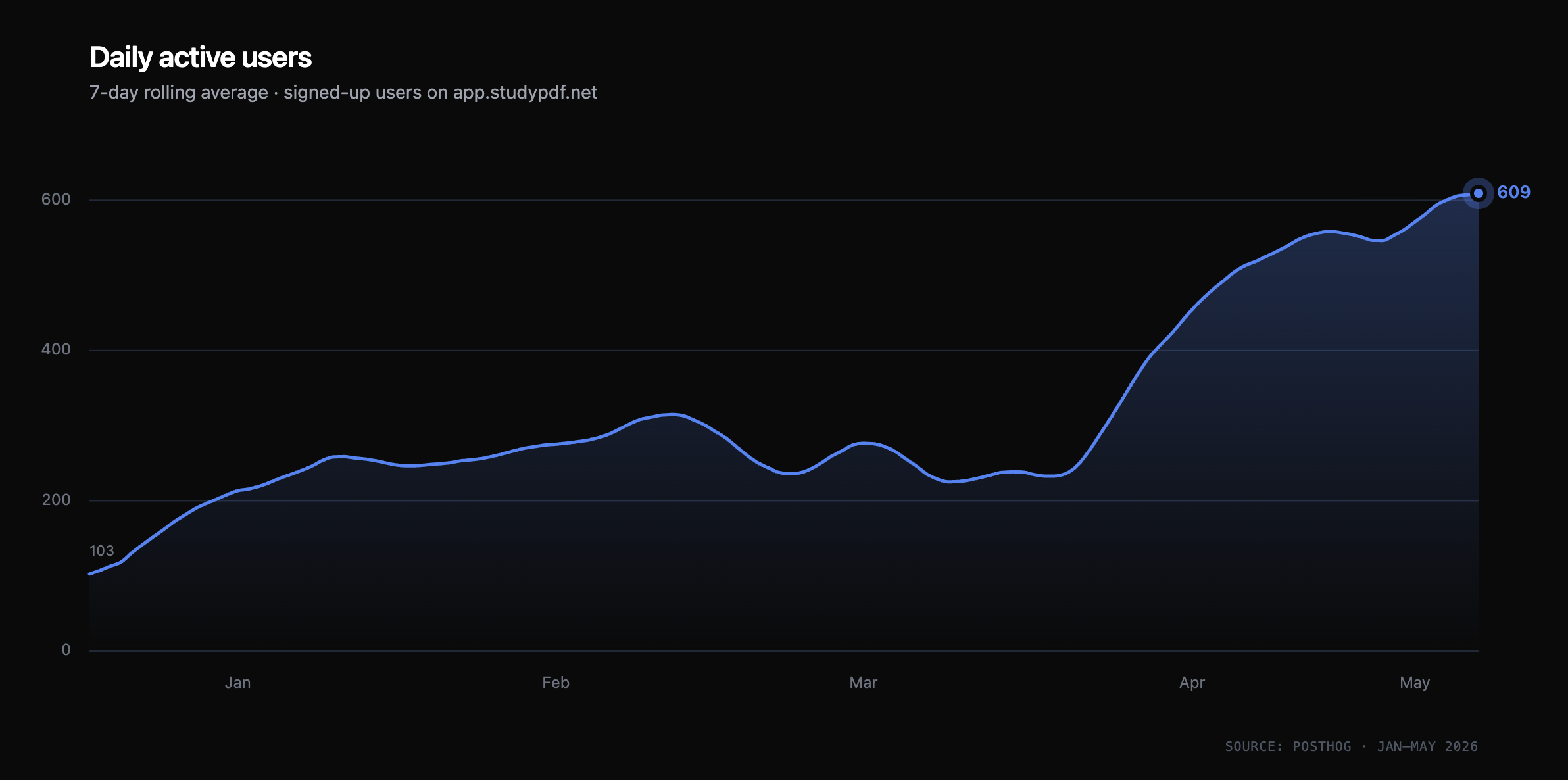
Daily active users (signed-up only) since I set up proper analytics in late 2025. The product had been running for over a year before this graph starts. The curve since then is what convinced me this is more than a side project.
2. A/B test iteration. I run a lot of tests: onboarding copy, paywall placement, free-tier limits. An agent builds the variant behind a feature flag, deploys it, and 48 hours later I get a summary of the result. The iteration speed compounds: I can run five to six small tests a week instead of one careful test a month. Then we also pass these results to the KPI monitoring agent to keep the context fresh and up to date.
3. SEO and GEO content at scale. A huge part of my growth, around 99%, is organic. Users come because they searched "study guide creator AI" or asked an LLM the same question. I have a content pipeline where agents draft long-form articles, I edit, we publish. That's how the curve above happens without spending a euro on ads. Paired with i18n internationalization, we ship the same blog articles in German and Spanish too. So each article, each page drives traffic from three languages.
The honest part: agents are very good at shipping what you tell them. They are bad at telling you what to build. Taste is still my bottleneck. What to build next, what to kill, how to talk to users, when the model output looks fine but is actually wrong. The agents shrink the gap between deciding and shipping; they don't shrink the gap between confused and clear.
What almost broke
Two stories.
The BMW night. In late 2024 and early 2025 I was doing an AI engineering internship at BMW in Munich. Long days, real responsibilities, a team I respected. One evening I pushed a small change to StudyPDF's onboarding flow and didn't test it well enough. The next morning, every new user got stuck in a state loop. They signed up, and then couldn't reach the dashboard. Three days like that. And, of course, that exact week was the biggest traffic spike StudyPDF had ever seen up to that point. Hundreds of new sign-ups landing on a broken product. I couldn't fix it during the day. I was at BMW. So I debugged until 2am, three nights in a row, in my small, way too expensive room in Munich. The fix was small. The lesson was: solo means every untested change can break for hundreds of users in production, and you're the only one to fix it. If you don't have time, you find time.
The Madeira incident. Earlier in 2024 I went on holiday to Madeira. On the first day, users started reporting that their flashcards had content from other people's documents. I was using OpenAI's Assistants API at the time, and under concurrent load, vector stores were getting contaminated across users. I debugged this for four hours on an otherwise beautiful day, inside the apartment. I thought I'd fixed it. Three days later it happened again. Two weeks of intermittent contamination, working from a laptop on holiday, eventually ending in the decision to drop the Assistants API entirely and build my own RAG layer. It was the right call. It also taught me something about depending on someone else's beta infrastructure as a solo operator: you don't have a team to absorb the variance. So you have to build with safe, stable, and proven methods.
What I'm building next, and what's still hard
The next thing on my list is an evaluation system for the multi-agent pipelines. Right now I check quality by hand and by user signal, which works at this scale but won't at 10x. I want something closer to: for every concept extraction run, score it against a ground-truth set; alert me when the distribution drifts. This is the kind of thing big labs do internally. I'm curious how to do it well as a single person.
There's also the harder problem I haven't solved yet, which is worth a whole post on its own: 85% of my users come to StudyPDF for an exam.
In-app survey from May 2026, n=83. The product-market fit is also the product-retention problem.
They use the product intensely for two weeks, they pass, they leave, they come back next semester. That's a beautiful adoption pattern and a terrible retention pattern. Duolingo solved this for languages. Nobody has solved it for exam-cycle learning yet. I have hypotheses, no answers. I'll write that one when I have something honest to say.
If you're working on hard problems in applied AI, particularly around evals, agent orchestration, or deployment for early-stage teams, I'd love to talk. Find me at studypdf.net, luishenrich.com, or @luisnhenrich on X.